With Eclipse 3.5 comes the new version of Xtext, called TMF Xtext. Since I had to switch to Eclipse 3.5 in order to keep GEF3D running on the latest Eclipse version, I decided to migrate from the old openArchitecture Xtext (oAW Xtext) to the new TMF version.
Fortunately the Xtext documentation contains a section about migrating from oAW Xtext to TMF Xtext. Frankly, I was a little bit afraid (never change a running system). But at least I hadn't implemented any content assist or other editor extensions yet, so I hoped that it wouldn't be too hard.
Before you read on, please note that I'm only an Xtext
user. I don't know any internal details about Xtext. Maybe some of my problems can be solved more efficiently, if that is the case, I would be more then happy if you leave me a comment. My first intention was to migrate my already running grammar as fast as possible, with as few modifications as possible.
The Setting
I have written a model transformation language, and it consists of an Xtext grammar (with about 90 rules), an interpreter for executing the language, and other things which I didn't expected to be involved in the migration, as a debugger component or other user-interface stuff. An Xtend-based M2M transformation exists which modifies the generated ecore model in order to set some default values, add some workarounds for existing oAW bugs, and do other things. In order to migrate my application, I had to
- migrate the grammar
- adapt the M2M-transformation
- adapt client code which uses the model and the Xtext API
In the following old versions are highlighted with a light red back and the new ones with a light green background.
Migrating the Grammar
As described in the Xtext documentation, I had to replace "Enum" with "enum", and add two new lines at the beginning of the grammar.
Since "with" has become a keyword. Thus I had to rename "with" in my grammar :
RuleXY: ... ( "with" with=Block)? ...
into
RuleXY: ... ( "with" _with=Block)? ...
This also caused some small changes in the model and the client code. Is there a way to use Xtext keywords as a reference names?
Backtracking
Apparently the parser generation (or some settings) has changed, too. E.g., the following rule worked with the oAW Xtext version:
ParameterReference: QualifiedParameterReference|SimpleParameterReference;
SimpleParameterReference: type=Type (name=ID)?;
QualifiedParameterReference: type=Type name=ID;
The idea of these rules is to force the definition of a name in case of qualified parameter references and to make it optional in simple ones.
Unfortunately these rules are not working with the new version. Since ANTLR is a LL-parser, there are some constraints on how to define the grammar. There is a
document explaining how to remove backtracking from a grammar, unfortunately some of the described techniques cannot be used with Xtext. In some cases I was able to fix the problem by rewriting my grammar, as in this example: I simply had to reorder the first rule:
ParameterReference: SimpleParameterReference|QualifiedParameterReference;
SimpleParameterReference: type=Type (name=ID)?;
QualifiedParameterReference: type=Type name=ID;
In some cases I couldn't find a solution (maybe it is possible, but I'm not an LL/LR-expert). Actually I'm not the first one with this problem, and there is a posting in the TMF newsgroup about this. If you cannot rewrite your grammar, you need backtracking (and lookahead).
Thanks to this posting, I was able to fix the problem. I had to edit the MWE-file from
<fragment class="org.eclipse.xtext.generator.AntlrDelegatingFragment" />
to
<fragment class="de.itemis.xtext.antlr.XtextAntlrGeneratorFragment">
<options k="2" backtrack="true" memoize="true"/>
</fragment>
Note that you have to install the itemis generator fragment from
http://download.itemis.com/updates as described in the Xtext documentation (page 62).
Maybe I'm going to "left factor" my grammar in a future version, but for now I only wanted to get my application running.
Lexer Rules
In the oAW version, lexer rules were defined with the keyword "native", which has been changed to "terminal". Not mentioned in the migration guide yet: INT was redefined in the new version. I had rewritten the definition in the old version in order to remove the optional sign (as my language is handling this itself). This is the old INT definition:
Native INT: ('-')?('0'..'9')+
And here's the new one:
terminal INT: ('0'..'9')+
In my case I could remove my own definition since the new one matches my requirements. In other cases, this might be a trap.
According to the documentation, it should be possible to define the type of a terminal rule now. I tried this as follows:
terminal FLOAT returns ecore::EFloat: ('0'..'9')*'.'('0'..'9')+;
As a matter of fact, the code is generated as expected, but the parser still returns a String, which leads to a ClassCastException. So I removed the type definition and added a convenient method to my model, as described below. I assume this is a bug or something, I will file a report later on ;-). Since the old version always returned Strings, my code was prepared for that, anyway.
OrmPackage missing
I don't know exactly why or when, but at some point in time my grammar file contains got an error marker:
- WrappedException: java.lang.ClassNotFoundException: com.sun.java.xml.ns.persistence.orm.OrmPackage"
This
bug seems to be fixed already, fortunately it is possible to generate the model and code from the grammar, even with this error.
Unassigned Actions
In the oAW Xtext version, a model element was assigned whenever a non-abstract rule was hit. My grammar contained the following rule:
NullLiteral: "null";
This rule is not working with the new TMF Xtext version. As found in the documentation "by default the object to be returned by a parser rule is created lazily on the first assignment". Although I've read that passage, I was not aware of the consequences. In the new version, an element is not automatically created when the rule is hit, but only when an assignment is to be executed. That is, a rule which contains only terminals does not create a model element, as in the example above. While this first example is obvious, the problem is sometimes hidden. Here is another more tricky example:
Block: "{" (statements+=BlockStatement)* "}";
If no "BlockStatements" are specified, that is in case of an empty block ("{}"), no block element is created at all. I posted that problem to the newsgroup, and Sebastian Zarnekow immediately
solved my problem (Thank you very much, Sebastian!).
The solution is to use
unassigned actions, which forces the creation of an element of the specified type. So I had to change the rules above as follows:
NullLiteral: {NullLiteral} "null";
Block: {Block} "{" (statements+=BlockStatement)* "}";
I figure this is a bitchy trap, especially if there is an optional assignment.
Model Changes
I'm already using an Xtend M2M-transformation to adjust the generated ecore model. TMF Xtext supports this mechanism, I simply had to rename my Xtend extension into MitraPostProcessor.ext (Mitra is the name of my language, by the way).
Enumeration NULL values
There are some adjustments necessary due to changed behaviour of Xtext. Most notable: There is no "NULL" value generated for enumerations. Also, it is not possible to define a hidden enumeration in the grammar, which might could have solved that problem. IMHO, this is a major drawback, as this makes a postprocessing of the created ecore file necessary.
But they can be added to the M2M transformation. Unfortunately, I didn't got this problem solved with Xtend, I posted that to the
TMF newsgroup. This is at least one solution using Java, although I would prefer a pure Xtend solution:
process(ecore::EPackage p):
addNullValue(p, "VisibilityModifier") ->
... ;
Void addNullValue(ecore::EPackage p, String toEnum):
doAddNullValue( (ecore::EEnum) p.getEClassifier(toEnum) );
Void doAddNullValue(ecore::EEnum e):
JAVA de.feu.MitraPostProcessorHelper.addNullValue(org.eclipse.emf.ecore.EEnum);
And this is the Java extension:
public class MitraPostProcessorHelper {
public static void addNullValue(org.eclipse.emf.ecore.EEnum e) {
for (EEnumLiteral literal : e.getELiterals()) {
literal.setValue(literal.getValue() + 1);
}
EEnumLiteral nullLiteral = EcoreFactory.eINSTANCE.createEEnumLiteral();
nullLiteral.setName("NULL");
nullLiteral.setLiteral("NULL");
nullLiteral.setValue(0);
e.getELiterals().add(0, nullLiteral);
}
}
In order to make a literal the default value, it must be the
first defined literal. This is why
e.getELiterals().add(0, nullLiteral); is required, simply adding the literal with
e.getELiterals().add(nullLiteral); doesn't work.
Java Body Annotation in the Ecore Model
In the old version, Xtext didn't create the genmodel and no code. I added this feature and I also edited the generated code after is was created using oAW extension. Since Xtext is doing the code generation now automatically, I didn't feel that comfortable with manually editing the generated model code anymore. So I decided to add Java annotations to the ecore model in order to add some tiny helper methods. This is how body annotations are added to an ecore model in Xtend:
Void addJavaBodies(ecore::EPackage p):
let ecorePackage = p.getEcorePackage():
p.getEClassifier("Bounds").addOperation("isMany",
ecorePackage.getEClassifier("EBoolean"),
'return upper==-1 || upper>1;') ->
...;
/*
This is a hack in order to retrieve the ecore package itself. This is usually
done with a Java extension, but I did not want to add a Java extension here.
The trick is to retrieve the package by navigating to the container of an ecore
type (here a String).
*/
cached ecore::EPackage getEcorePackage(ecore::EPackage p):
(ecore::EPackage)
( ((ecore::EClass) (p.getEClassifier("MetamodelDeclaration")))
.getEStructuralFeature("type").eType.eContainer
);
create ecore::EOperation addOperation(ecore::EClassifier c, String strName, ecore::EClassifier type, String strBody):
setName(strName) ->
setEType(type) ->
eAnnotations.add(addBodyAnnotation(strBody)) ->
((ecore::EClass)c).eOperations.add(this);
create ecore::EOperation addOperation(ecore::EClassifier c, String strName, ecore::EClassifier type,
List parameters,
String strBody):
setName(strName) ->
setEType(type) ->
parameters.collect(e|((List)e).setParameter(this)) ->
eAnnotations.add(addBodyAnnotation(strBody)) ->
((ecore::EClass)c).eOperations.add(this);
create ecore::EParameter setParameter(List parameter, ecore::EOperation op):
setName((String)parameter.get(0)) ->
setEType((ecore::EClassifier) parameter.get(1)) ->
op.eParameters.add(this)
;
create ecore::EAnnotation addBodyAnnotation(ecore::EOperation op, String strBody):
setSource("http://www.eclipse.org/emf/2002/GenModel") ->
this.createBody(strBody) ->
op.eAnnotations.add(this);
create ecore::EStringToStringMapEntry createBody(ecore::EAnnotation anno, String strBody):
setKey("body") ->
setValue(strBody) ->
anno.details.add(this);
API Changes
So far I found three API changes which required changes in my code. These changes are rather simple and briefly explained in the following.
NodeUtil.getNode(..)
First of all,
NodeUtil.getNode(EObject); has changed. There is no type
Node anymore. I had to change my code from
Node node = NodeUtil.getNode(eobj);
to
NodeAdapter adapter = NodeUtil.getNodeAdapter(eobj);
AbstractNode node = null;
if (adapter != null) {
node = adapter.getParserNode();
}
Resources and Setup
For (JUnit) tests, I have to call a setup method in order to register Xtext's resource implementations and my model. This is now simply achieved via a generated setup method. This is the setup method I'm using now in JUnit tests:
public static void setup() {
System.setProperty("org.eclipse.emf.ecore.EPackage.Registry.INSTANCE",
"org.eclipse.emf.ecore.impl.EPackageRegistryImpl");
MitraStandaloneSetup.doSetup();
No DSL-specific Editor Class
A little bit surprising at first is the absence of a DSL specific editor class, in my case
MitraEditor. Instead, the general Xtext editor class is used, DSL specifics are injected using Google Guice as described in the Xtext manual. Most surprising is the new syntax found in the plugin.xml which is used to inject things. Here is the declaration of my editor using the new notation (the plugin.xml is generated):
<extension point="org.eclipse.ui.editors">
<editor
class="de.feu.MitraExecutableExtensionFactory:org.eclipse.xtext.ui.core.editor.XtextEditor"
contributorClass="org.eclipse.ui.editors.text.TextEditorActionContributor"
default="true"
extensions="mitra"
id="de.feu.Mitra"
name="Mitra Editor">
</editor>
</extension>
The attribute "class" defines the Guice module to be created and the editor class. Unfortunately I need the editor class in order to add breakpoint markers (for my debugger plugin). The old version looks like this:
public class MitraBreakpointAdapterFactory implements IAdapterFactory {
public Object getAdapter(Object adaptableObject, Class adapterType) {
if (adaptableObject instanceof MitraEditor) {
...
How do I identify the mitra editor in the new version? First of all, instead of a generated DSL specific editor, an
XtextEditor is used (this class is found in plugin
org.eclipse.xtext.ui.core). Then the current language can be retrieved via
getLanguageName(). This is the new version:
public Object getAdapter(Object adaptableObject, Class adapterType) {
if (adaptableObject instanceof XtextEditor) {
XtextEditor xtextEditor = (XtextEditor) adaptableObject;
if ("de.feu.Mitra".equals(xtextEditor.getLanguageName())) {
...
Note that the name of the editor class has to be changed in the plugin.xml of the debug plugin accordingly.
Summary
After applying the changes described above, my language worked as expected (at least all the tests are green and my application is running). Since I haven't written any extensions for content assist or other UI things, I only had to adjust the grammar, my M2M-transformation and the code a little bit. If you do not have an M2M-transformation, you may have to add it in order to add the missing NULL values for enumerations -- I assume this is the case quite often.
TMF Xtext adds some very nice features (grammar mixings, improved linking/cross references feature with ILinkingService, serialization with formatter, return types, and tree rewrite actions). These features will simplify my hand written code immensely, and I'm looking forward using them. Last but not least, since Xtext is now part of the Eclipse modeling package, it is much easier to install an Xtext based DSL and editor.
Last but not least: Kudos to the Xtext team! The new version looks really nice! And many thanks for the great and fast (newsgroup) support!
 Fig 1: Kristian's 3D GMF Mapping Editor
Fig 1: Kristian's 3D GMF Mapping Editor Fig. 2: Visualization of metrics with GEF3D
Fig. 2: Visualization of metrics with GEF3D
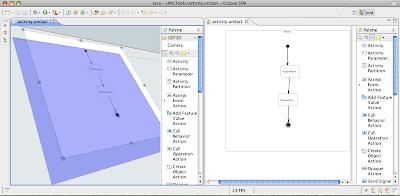 The 3D version of the UML Tool's activity diagram editor (on the right hand side, 2D version on the left). Note the 3D handles and the transparent feedback figure!
The 3D version of the UML Tool's activity diagram editor (on the right hand side, 2D version on the left). Note the 3D handles and the transparent feedback figure!
 The original GEF3D diagram is shown at the bottom left. The large diagram is the very same image, exported as X3D and viewed with the instantplayer. The small image on the top left shows the very same X3D file, this time rendered with the Octaga Player.
The current version of the X3D exporter is only a beginning. We certainly have to improve the quality of the diagrams, but it shows what is possible. Maybe other programmers write other cool renderers for GEF3D in the future ;-)
The original GEF3D diagram is shown at the bottom left. The large diagram is the very same image, exported as X3D and viewed with the instantplayer. The small image on the top left shows the very same X3D file, this time rendered with the Octaga Player.
The current version of the X3D exporter is only a beginning. We certainly have to improve the quality of the diagrams, but it shows what is possible. Maybe other programmers write other cool renderers for GEF3D in the future ;-)
 After getting the preliminary approval I've just committed the initial GEF3D contribution into the SVN (GEF3D is participating in the parallel IP process).
You can now check out GEF3D from
svn://dev.eclipse.org/svnroot/technology/org.eclipse.gef3d
In order to test GEF3D, you'll need the following projects (please add org.eclipse to the name):
draw3d, draw3d.geometry, gef3d, gef3d.ext, gef3d.gmf, and gef3d.examples.graph
Optionally you can check out the test and documentation projects, however there are currently not much tests and documentation available (but you can use the ant script in doc in order to generate the JavaDoc).
Draw3D, the 3D version of Draw2D, needs a renderer module in order to produce any output. Currently, only LWJGL is supported (or.eclipse.draw3d.lwjgl). The module only contains the Draw3D specific code, additionally you will need the LWJGL libraries. These are available via the LWJGL update site at http://lwjgl.org/update. An description can be found at
http://www.fernuni-hagen.de/se/personen/pilgrim/gef3d/lwjgl.html.
The GEF3D example is running, but there is a known bug. We are working on that already... Actually there are more bugs known, we will add them to Bugzilla as soon as possible ;-)
After checking out all these projects, the example editor can be activated by simply creating a file with appropriate extension: ".graphSample" for the 3D editor, ".graphSampleDia" for a 2.5D editor (i.e. 2D figures projected on 3D planes), and ".multiGraphSample" for a multi plane editor.
Update: The current installation instruction can be found at http://wiki.eclipse.org/GEF3D.
After getting the preliminary approval I've just committed the initial GEF3D contribution into the SVN (GEF3D is participating in the parallel IP process).
You can now check out GEF3D from
svn://dev.eclipse.org/svnroot/technology/org.eclipse.gef3d
In order to test GEF3D, you'll need the following projects (please add org.eclipse to the name):
draw3d, draw3d.geometry, gef3d, gef3d.ext, gef3d.gmf, and gef3d.examples.graph
Optionally you can check out the test and documentation projects, however there are currently not much tests and documentation available (but you can use the ant script in doc in order to generate the JavaDoc).
Draw3D, the 3D version of Draw2D, needs a renderer module in order to produce any output. Currently, only LWJGL is supported (or.eclipse.draw3d.lwjgl). The module only contains the Draw3D specific code, additionally you will need the LWJGL libraries. These are available via the LWJGL update site at http://lwjgl.org/update. An description can be found at
http://www.fernuni-hagen.de/se/personen/pilgrim/gef3d/lwjgl.html.
The GEF3D example is running, but there is a known bug. We are working on that already... Actually there are more bugs known, we will add them to Bugzilla as soon as possible ;-)
After checking out all these projects, the example editor can be activated by simply creating a file with appropriate extension: ".graphSample" for the 3D editor, ".graphSampleDia" for a 2.5D editor (i.e. 2D figures projected on 3D planes), and ".multiGraphSample" for a multi plane editor.
Update: The current installation instruction can be found at http://wiki.eclipse.org/GEF3D.

